Thriving Traction | Stochastic Ensemble Value Expansion (STEVE) Model for Low Sample Datasets
Reinforcement learning (RL)is a framework of trial and error; the system makes short-term decisions while optimizing long-term goals. Having the ability to interact with the environment, the aim of any RL technique is to maximize the expected reward and minimize the number of interactions, i.e. to achieve sample efficiency. But to perform well, modern RL techniques need comparatively more data, which makes them sample inefficient.
RL techniques can be categorized as:
- Model-Free RL: Uses the action in an environment to learn the policy while maximizing the reward.
- Model-Based RL: Learns the dynamics of the environment and predicts the next state and reward before taking an action.
Knowing the dynamics of the environment beforehand is better than knowing just the rewards, which makes model-based RL more sample efficient than model-free RL. But model based RL has its own drawbacks, such as approximation errors (in estimating model and value function) and inaccurate models that lead to suboptimal policy computation. Computationally, it is also more complex.
To resolve the issues with both technique types, recent research, and development in the uncertainty-aware hybrid technique (built by integrating model-free and model-based RL techniques) have demonstrated high performance. Stochastic Ensemble Value Expansion (STEVE)[1] is one such technique that can enable the use of RL in practical real-world problems.
RL Techniques
Before diving into STEVE, we need to understand a few RL techniques:
- Q-Learning: Q-learning utilizes q-values or action values to iteratively improve the learning agent’s behavior. They are characterized by actions and states. Q (S, A) is an assessment of how great it is to make the move A at the state S; this assessment is computed utilizing TD learning. [2]
- Temporal Difference (TD) Learning: TD learning is a model-free RL technique in which the agent doesn’t have prior knowledge of the environment; it learns through episodes of trial and error from the environment. It is represented as Q(S,A)←Q(S,A)+ α(R+ γQ(S’, A’ ) -Q(S,A)) , where S is the agent’s current state, A is the current action taken based on the policy, R is the reward, Υ is the discounting factor and α is the step length taken for updating Q(S, A).[2] On generalizing, the TD update can also be represented as:

At every time step, the agent interacts with the environment and the q-value’s estimate is computed using the above TD update rule.
- Model-Based Value Expansion (MVE) Learning: MVE is a hybrid technique that combines model-based and model-free learning by incorporating a model into the q-value target estimation. This incorporation of a learned dynamics model within a model-free technique improves value estimation and reduces sample complexity. The uncertainty in the model is also controlled by fixing the model to run for a certain depth (H). The MVE target for H = 3 is represented as: [3]
 However, in an adequately complex environment, the learned dynamics model will quite often be imperfect; this is again a challenge in combining MF and MB techniques.
However, in an adequately complex environment, the learned dynamics model will quite often be imperfect; this is again a challenge in combining MF and MB techniques.
STEVE – An Extension of MVE
STEVE, a novel model-based technique developed by Google Brain, is an extension to the MVE. Specifically, it addresses the issues faced in the MVE. Both models try to improve the target for TD learning by using a dynamic model to compute the rollouts in such a way that performance is not degraded due to the model’s error.
MVE uses a model and q-learning for the computation of interpolated targets with a fixed-length rollout into the future, certainly collecting the model error. “In STEVE, the model and the Q-Learning are replaced by the ensembles, approximating the uncertainty of an estimate by computing its variance under samples from the ensemble”.[4] By calculating the uncertainty, STEVE utilizes the model rollouts dynamically only when they don’t introduce huge error.
In a single rollout with H timestep, H+1 different candidate targets can be computed by considering rollouts to numerous horizon lengths, such as![]() . The target in standard TD learning is
. The target in standard TD learning is ![]() . In MVE, the target is
. In MVE, the target is ![]() [1]. In STEVE, the target is the interpolation of all the candidate targets, which in naive terms can also be said as averaging the candidate targets or weighing them in an exponential decaying method in such a way that it balances the error from both the learned q-function and the longer model rollouts. The implementation from Google Brain is present here for different continuous control tasks using STEVE.
[1]. In STEVE, the target is the interpolation of all the candidate targets, which in naive terms can also be said as averaging the candidate targets or weighing them in an exponential decaying method in such a way that it balances the error from both the learned q-function and the longer model rollouts. The implementation from Google Brain is present here for different continuous control tasks using STEVE.
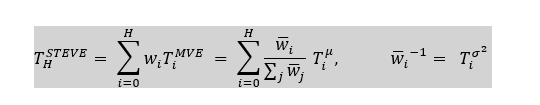 Where,
Where, ![]() is empirical mean and
is empirical mean and ![]() is the variance corresponding to partial rollout of length i.
is the variance corresponding to partial rollout of length i.
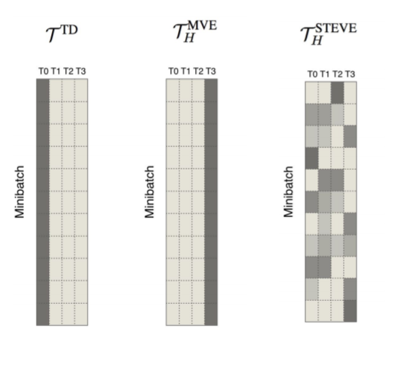
Comparison of TD, MVE and STEVE Learning Process, Source – https://danijar.com/asset/steve/poster.pdf
Real-Time RL Data Science Applications
The aforementioned technique paves the way for incorporating RL into complex real-life data science problem where supervised and unsupervised models cannot help. Training an RL model for real-world tasks is extremely challenging. Also, the disadvantage of needing more data commonly makes the task of training an RL model infeasible. Some of the data science applications where this methodology can be incorporated despite having less data are:[5]
- Digital Marketing: When limited user data makes it difficult to deliver personalized recommendations, RL can produce high-quality recommendations by dynamically capturing user behavior, preferences, and requirements.
- Chatbots: Chatbot offerings can be improved by using RL to leverage data from user communications.
- Predicting Future Sales and Stock Prices: Prediction models for future sales and stock prices can be easily developed, but these models cannot determine what action to take at a certain stock price on which an optimally trained and performing RL model can efficiently decide whether to buy, hold, or sell.
- Large-Scale Production Systems: RL-based platforms can be used to optimize large-scale production systems. An exemplary example of RL in video display is serving a client a low or high bitrate video, depending on the condition of other AI frameworks’ estimates and video buffers.
- Marketing and Advertising: The ability to precisely focus on the individual is extremely significant in marketing; hitting the right targets clearly leads to exceptional returns. RL can be incorporated into such tasks, as policies can be trained to handle complex environments.[6]
- Revenue and ROI (Return on Investment): These can be maximized by optimal and relevant ad/promotion placement based on the user’s interest via real-time advertising. But the most essential thing is that it requires a strategic response and real-time bidding, due to the different advertiser bidding in the market; this requires a dynamic model. [7]
References
[1] Stochastic Ensemble Value Expansion
[3] Model-Based Value Expansion for Efficient Model-Free Reinforcement Learning
[4] Sample-Efficient Reinforcement Learning with Stochastic Ensemble Value Expansion
[5] Real-Life Applications of Reinforcement Learning
[6] Business Use-Case of Reinforcement Learning in Trading
[7] Real-Time Bidding with Multi-Agent Reinforcement Learning
Authored by Darshita Rathore, Analyst, Navik and Analytics, at Absolutdata




















