Thriving Traction | Best Practices in Data Science
Given how much of our world is fueled by data, we may understandably wonder what data science’s future will hold. While it’s difficult to predict with any certainty what the future’s defining innovations will be, Machine Learning appears to be of the utmost importance. Data scientists are looking for new ways to leverage Machine Learning to create more advanced, self-aware AI.
In a world that is more linked than ever, experts forecast that AI will be able to comprehend and communicate with humans, autonomous vehicles, and automated public transportation systems with ease. Data science will make this new world conceivable. The capacity for sales and marketing teams to thoroughly understand their customer is one of the most talked-about advantages of data science. An organization may design the finest customer experiences by using this information. The healthcare, financial, transportation, and defense industries are anticipated to undergo a revolution as a result.
Emerging Data Science Best Practices
1. Choosing a data versioning tool
- Data modality: Based upon the preview of the data.
- Practicality: Whether the tool can be implemented in the project workflow.
- Comparison of the data sets: Data needs to be in a format that can be easily compared to the data sets’ flow.
- Infra integration: Whether the tool can work within with the Infrastructure or data modeling workflow.
- Examples of data version control tools:
- Neptune
- Pachyderm
- LakeFS
- DVC
- Dolt
- Delta Lake
- Git LFS
2.Making data quality systematic
The most important factor is data consistency. We must utilize methods that enhance the data quality and enable models to perform well. We must also maintain the code while continually improving the data.
- Request sample labeling by two independent labelers.
- Compare labelers’ consistency to identify areas of disagreement.
- When labelers disagree about a class, the labeling guidelines should be changed until everyone agrees.
- Consistency in labeling and small data is paramount.
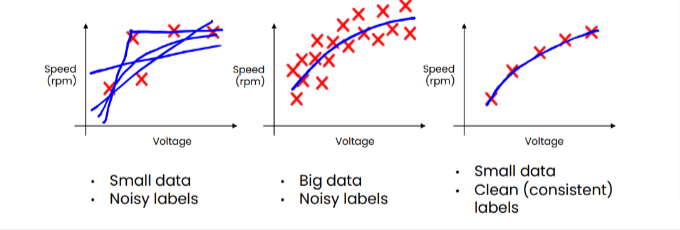
3. From Big Data to Good Data
MLOps’ most important task is to ensure constant high-quality data over the whole lifespan of the project. Good data has:
- A consistent definition.
- Clear labels.
- Good coverage of main cases.
- Coverage for concept and data drift.
- Timely feedback.
- The appropriate size.
- AI system = Code + Data.
4. Iterative evaluations
While the traditional software development process may end with functionality deployment (without taking into consideration update cycles), this is not the case with data-centric ML initiatives. The ML model in production will use data that it has never seen before; this data will certainly be different from the algorithm’s training data.
As a result, the quality of the model should be evaluated throughout the process. It should not be seen as a last step. A requirement for online learning is the timely input from production systems, which, for instance, enables the identification and response to distributional data drifts.
5.Data augmentation
Different techniques for boosting the quantity of sample data points include creating new images by flipping, rotating, zooming, or cropping existing ones; similar methods exist in language processing. Data augmentation is used in data-centric Machine Learning to enhance the quantity of pertinent data points, such as the number of faulty production components.
Businesses must change and expand along with AI technology, which is never static. Data quality is a key component of the move from model-centric to data-centric AI. A new kind of Artificial Intelligence technology called data-centric AI (DCAI) is devoted to comprehending, exploiting, and reaching conclusions from data. Prior to data-centric AI, AI relied mostly on rules and heuristics. While they might be helpful in some circumstances, they frequently produce less-than-ideal outcomes or even mistakes when used with new data sets.
By adding Machine Learning and Big Data analytics tools, data-centric AI enables systems to learn from data rather than depending on algorithms. They can thus make wiser choices and deliver more precise outcomes. Additionally, this method has the potential to be far more scalable than conventional AI. As data sets get bigger and more complicated, data-centric AI will become more significant.
References
Neptune AI: Best Data Versioning Tools
Dataquest: Evolution of Data Science Growth
IntechOpen: Best Practices in Accelerating the Data Science Process
DataCentricAI.org: What Is Data Centric AI?
Brown, Sara: Data Centric AI in Demand
Authored by: Piyusha Pandit, Senior Program Engineer at Absolutdata




















