Statistictionary | Mathematical Formulation of Optimal Policy
Reinforcement Learning:
Reinforcement learning is another branch of machine learning after supervised and unsupervised learning. It is used to make sequential decisions while training machine learning models. As per the following flow diagram, in an uncertain and complex environment, an agent focuses on maximizing the reward and learn to achieve goal. It is basically controlling the machine to do what a programmer wants by either rewarding or penalizing the actions it performs. [1]
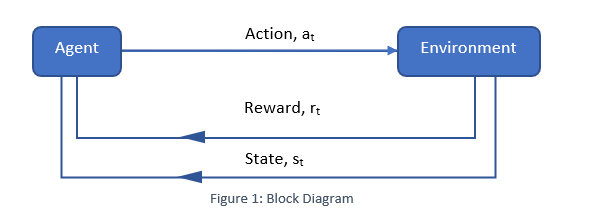
A reinforcement learning problem consist of various technical components including states, actions, transitions, rewards, policies, and values where:
- States are visitable positions.
- Actions are possible movements.
- Transitions specify connections between states via actions. Thus, knowing the transitions means knowing the map.
- Reward specifies the evaluation of that action.
- A policy specifies an action the agent takes at each state. Thus, a policy also specifies a trajectory, which is a series of states and actions that the agent takes from a start state to an end state.
Optimal Policy Formulation [2]:
Understanding of reinforcement learning requires exploration of fundamental mathematical backing. The following formulas are being used and manipulated as per the environment and goal. Under a discrete time Markov decision process (MDP)[3] Lets consider the problem of controlling a computer agent at each discrete time-step t, the agent observes a state st ∈ S, selects an action at ∈ A, makes a transition st+1 ∈ S, and receives an immediate reward. Where:
- S is finite set of states
- A is finite set of actions
- R: S × A → R is a reward function
- r (st, at, st+1) is called the immediate reward function
Basically, each possible next state st+1 is determined with probability p(st+1|st, at), and action at is chosen using the policy π(at/st). Along a trajectory (h), we sum over all such possible next states.[4] As mentioned, The goal is to maximize the expected return by learning the optimal policy which is denoted as π*:
π* = argmaxπEpπ(h)[R(h)] Where:
- argmax gives max of a function and Epπ(h) denotes expectation over trajectory h drawn from pπ(h) .
- R(h) is discounted sum of immediate rewards along the trajectory (h) and is called the return. This is the reward or penalty that agents get by performing an action. It is discounted as per the environment so that agent reaches goal by maximising the reward. This also helps agent become more farsighted where it explores all possible combinations.
- The policy(π) defines the agent behaviour and maps the state of environment to actions. It is a conditional probability density of action a at state s.
- pπ(h): denotes the probability density of observed trajectory h under policy π.
References:
- Deepsense.ai “What Is Reinforcement Learning? The Complete Guide
- Suguyama, Masashi. Statistical Reinforcement Learning: Modern Machine Learning Approaches
- wikipedia.org “Markov Decision Process”
- Reinforcement Learning -Chapter 18 – IITK
Authored By Rohan Garg ,Data Scientist at Absolutdata




















