Coder’s Cauldron | Reinforcement Learning – An Example Using the OpenAI Cart Pole Problem
Introduction
There are many real-world problems that do not fall in the traditional problem-solving approaches of supervised and unsupervised learning in machine learning. Complex, uncertain, and real/simulated environments require a methodology where the model being trained can make decisions by itself to achieve an overall objective.[1] For example, think of building a model to drive an automated car, play Chess or Go, control a prosthetic foot, make a robot walk an obstacle course, or plan inventory/investments for a business.
Here, the agent must learn by trial and error in a gamified scenario with built-in rewards and penalties. The problem designer sets the rewards but gives no hint to the model on how to progress. The RL model starts with random trials and iteratively gets better until it achieves dexterity in the stated task. Since this process can be parallelized, training time can be shortened exponentially by exploiting modern computing hardware.
OpenAI Gym
Since RL models are trained to solve specific problems, small variations in problem definition (like rewards and penalties) can greatly alter the difficulty. Thus, it is important to have a standardized, open-sourced collection of diverse environments. OpenAI provides a good collection of standardized problems (environments) with its Gym toolkit.[2] Here one can learn, develop and benchmark RL models. It’s simple to install:
pip install gym
or
conda install gym
Cart Pole Problem
Let’s look at one of the classic problems available in the Gym: CartPole-v0. This simulates a vertical pole attached to a cart with a movable hinged joint – basically an inverted pendulum. All of us might have tried balancing a pole in our hands at some point! It’s a trivial task for humans, but not for machines.
In the stated problem, the cart can move sideways in both directions. The objective is to maintain this inverted pendulum configuration; a reward of +1 is awarded for every time interval the pole is upright. The model can apply a force to the cart in either direction. The penalty is an end to the game if the pole is more than 15 degrees off from vertical or the cart is more than 2.4 units from the starting position. The problem is considered solved if a reward of more than 195 is achieved over 100 consecutive trials. The model must learn to keep the pole upright. [3,6]
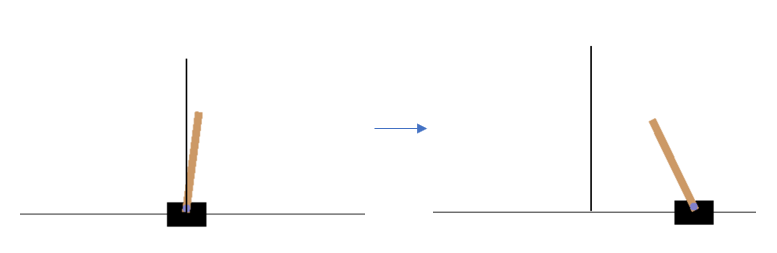
Random Solution
A basic implementation of this environment can be done in the following few lines of code:

The above piece of code tries to keep the pole upright with random actions. The cart moves randomly along the horizontal axis until either 100 actions are completed or the terminating conditions are met. The action_space is either 0 or 1 (force to the left or right). Clearly, it is impossible to find a solution with random actions:

The complete cycle can be represented with the above diagram. Here the Environment is the pole and cart, the Agent is our model (random), the action is the application of force to the left or the right, and the observation is the state of the environment (indicating the angle of the pole and the cart’s distance from the initial position). The reward is +1 for every timestep the pole is upright.
Proximal Policy Optimization Approach
Let’s use a reinforced learning algorithm to introduce some intelligence in the system. We will implement a Proximal Policy Optimization (PPO) approach. The PPO algorithm is one of the most effective and popular RL algorithms. It was launched by OpenAI in 2017.
- PPO has two components: The Actor model and the Critic model. [4,5]
- The Actor learns what action to take given an environment state.
- The Critic model monitors the reward obtained once the action is applied to the environment. It learns if the action of the Actor resulted in a positive reward or a negative one and gives a score (rating) to the Actor.
- The Actor then decides how to update its current policy (actions) based on the rating received from the Critic model.
- PPO runs the whole loop with the two models for a finite number of steps. It observes this small set of observations after interacting with the environment and uses this batch to update its decision-making policy (action). This old batch is then discarded, and a new batch is created with the updated policy. This is an ‘on-policy learning’ approach. [8]
- The updating of the policy from the previous version is moderated, ensuring the training variance is limited. This avoids the agent going down a bad policy path and getting stuck there. To achieve this, we cap the ratio of new and old policy updates to a threshold value.
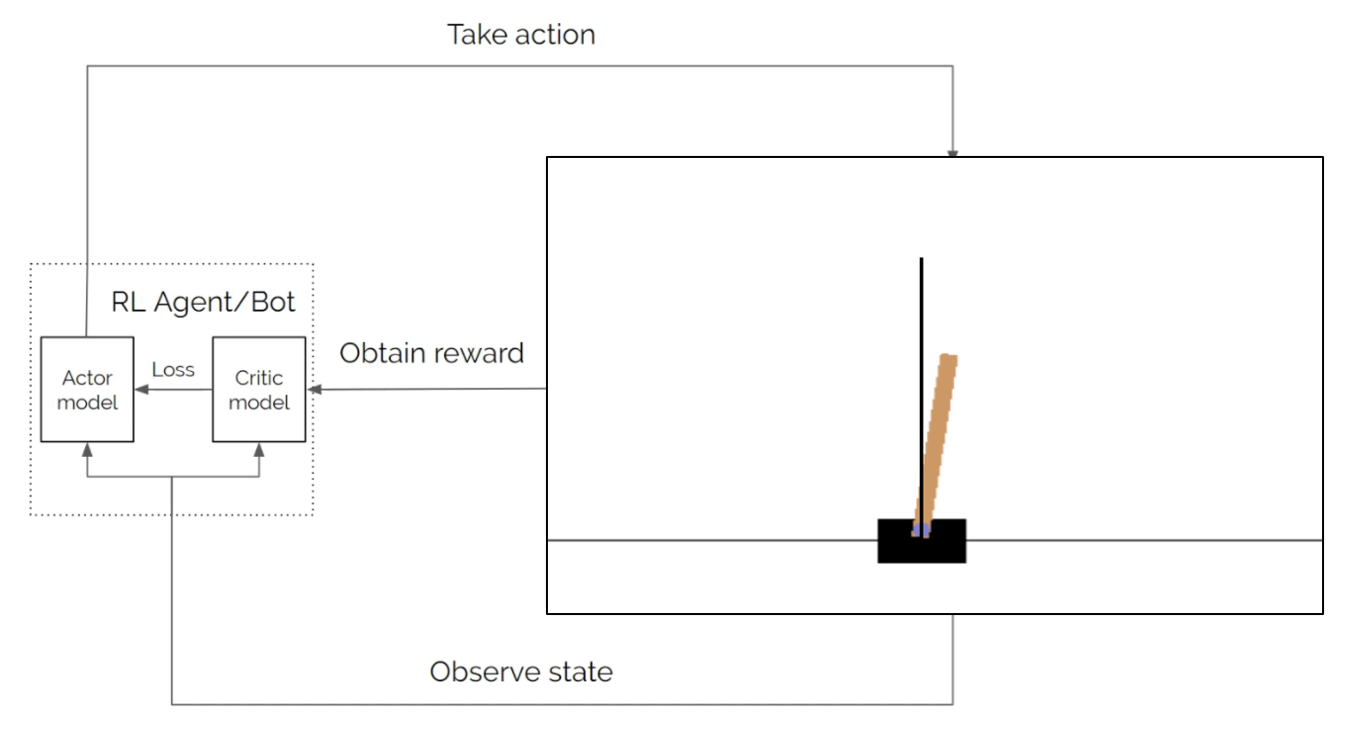
Image credits: PPO Hands-On Tutorial
You can implement this on your own using the code attached below.[7] For further reading, please check out the references.
Attachments:
References
[1] Introduction to Reinforcement Learning
[2] OpenAI
[3] Getting Started with OpenAI Gym
[5] RL Implementation for Cartpole
[6] Cartpole Documentation and Evaluations
[9] Cartpole Animation After 20 Epochs
Authored by Ankit Tyagi, Senior Consultant at Absolutdata




















